

Java Hashcode() Equals() Kontrakt Pod Lupą Juniora
![]()
Gdy moje dziecięce resoraki miały przyciemniane szyby, przez które nie można było zajrzeć do środka, ciekawość skutecznie namawiała mnie do demontażu takiej zabawki. Teraz, ucząc się Javy, jest podobnie. Nieraz mam potrzebę przeanalizowania zagadnienia bardziej szczegółowo niż dostarcza mi to zdawkowy tutorial czy przerabiany temat kursu. Klikam wtedy lawinowo w kolejne klasy bazowe i interfejsy, szukając źródła implementacji i testując kod na różne sposoby. Tym razem pod lupę trafił temat kontraktu pomiędzy metodą equals() i hashCode().
Co wiemy z podstaw
To, że metoda equals() powinna być zaimplementowana w klasie naszego obiektu, aby móc poprawnie porównywać ze sobą dwie instancje, jest oczywiste. To, że powinniśmy zaimplementować w naszej klasie obiektu metodę equals() wraz z metodą hashCode(), aby móc poprawnie operować na zbiorach lub mapach tych obiektów, też wiemy. Co się za tym kryje i dlaczego nie wystarczy do porównywania jedynie sama metoda equals() i po co angażować do tego hashCode(), lub odwrotnie? Odpowiedź związana jest z optymalizacją procesu porównywania obiektów.
Nauka przez doświadczenie
Proponuje wykonać szybki test, który pozwoli unaocznić zasadę działania kontraktu equals() - hashCode().
Moje obiekty testowe będą instancjami klasy Person:
public class Person {
private final String firstName;
private final String lastName;
private final Integer age;
@Override
public boolean equals(Object o) {
System.out.println("equals method initialized for " + firstName);
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(firstName, person.firstName) &&
Objects.equals(lastName, person.lastName) && Objects.equals(age, person.age);
}
@Override
public int hashCode() {
System.out.println("hashcode method initialized for " + firstName);
return Objects.hash(firstName, lastName, age);
}
W metodzie equals() oraz hashCode() dodałem linijkę z System.out-em aby doświadczyć w konsoli kolejność działań. Możnaby było skorzystać z debuggera, ale w tym przypadku czarno na białym zobaczymy obie metody w akcji.
Teraz czas na eksperyment. W klasie PersonApp dodajemy do zbioru nowe obiekty klasy Person, dwie unikatowe i trzecia taka sama jak pierwsza:
public class PersonApp {
public static void main(String[] args) {
Set<Person> persons = new HashSet<>();
Person lebowski1 = new Person("Jeffrey", "Lebowski", 45);
Person sobczak = new Person("Walter", "Sobchack", 45);
Person lebowski2 = new Person("Jeffrey", "Lebowski", 45);
System.out.println("Dodano lebowski1: " + persons.add(lebowski1) + "\n");
System.out.println("Dodano sobczak: " + persons.add(sobczak) + "\n");
System.out.println("Dodano lebowski2: " + persons.add(lebowski2) + "\n");
System.out.println("Ilosc dodanych osob: " + persons.size());
}
}W konsoli zobaczymy wydruk:
/*
hashcode method initialized for Jeffrey
Dodano lebowski1: true
hashcode method initialized for Walter
Dodano sobczak: true
hashcode method initialized for Jeffrey
equals method initialized for Jeffrey
Dodano lebowski2: false
Ilosc dodanych osob: 2
Dodane zostały dwie osoby: lebowski1 oraz sobczak, a lebowski2 został odrzucony.
Na obiekcie, na którego wskazuje referencja lebowski1, została wywołana metoda hashCode(). Wynik tego hashCodu() (wynikiem zwracanym jest wartość int, ale o tym później) został użyty do wyliczenia indeksu w tablicy haszującej. (tablica haszująca to wewnętrzna struktura, inicjalizowana przy pierwszym wywołaniu metody add, która przechowuje obiekt pod wyliczonym indeksem -miejsce w tablicy o tym indeksie nazywamy bucketem) a lebowski1 trafił do zbioru persons (a dokładnie referencja w w/w buckecie wskazuje na obiekt lebowski1).
Następnie na obiekcie sobczak została wywołana również jedynie metoda hashCode(). “Hashcode sobczaka” został przeliczony na indeks w tablicy haszującej, pod tym indeksem było pusto, więc sobczak trafił do tego bucketu, i tym samym znalazł się w puli naszego zbioru.
Zauważ, że do tego momentu nie została w ogóle wywołana metoda equals() do porównania, a mimo to obiekty lebowski1 oraz sobczak zostały uznane na różne. To właśnie dzięki wyliczonym HashCode-om, które były różne w tym przypadku i pośrednio wskazały dwa różne miejsca w tablicy haszującej.
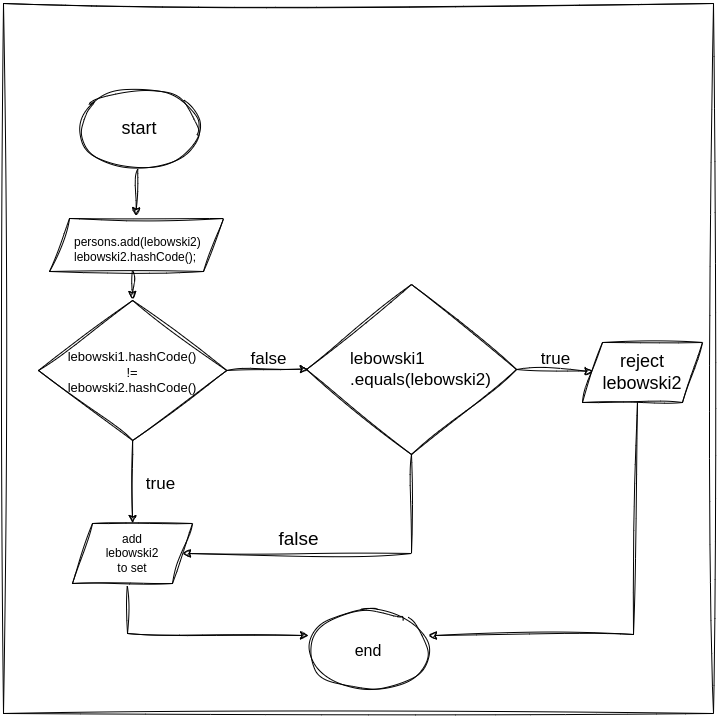
Ciekawiej jest w trzecim przypadku gdy dodajemy do zbioru obiekt lebowski2, który jest taki sam jak lebowski1 (taki sam pod względem wartości pól przekazanych w konstruktorze). W tym przypadku widzimy w konsoli, że zostaje uruchomiona najpierw metoda hashCode() a potem dodatkowo equals().
Jak przebiegał proces dokładnie? Wypunktujmy:
- uruchomiona zostaje metoda add na zbiorze: persons.add(lebowski2)
- wywołana zostaje metoda lebowski2.hashCode() - zwraca wartość int
- wartość int posłużyła dalej do wyliczenia indeksu w tablicy haszującej
- pod tym indeksem już znajduje się obiekt (lebowski1)
- porównywane są, wyliczone wcześniej, hash-e obu obiektów
- porównanie hash-y zwraca true, więc wywołana zostaje metoda equals()
- equals() zwraca true, więc lebowski2 zostaje odrzucony
Dla wzrokowców, poniżej wizualizacja powyższego procesu:
W tym momencie u mnie pojawiły się w głowie 2 pytania:
-
dlaczego zatem obiekt lebowski2 nie zostaje od razu odrzucony, skoro hash-e obu obiektów są takie same i wywołana zostaje dodatkowo metoda equals()?
-
lub dlaczego od razu nie zostaje wykonana na obu obiektach metoda equals(), bez zbędnego porónwywania hasz-y?
Odpowiedź na pytanie 1 : źródło implementacji, które doprowadziło do takiego wyniku znajdziemy w instrukcji warunkowej w pakiecie java.utils:
/*
if (p.hash == hash && ((k = p.key) == key || key != null && key.equals(k))) (1)
Ale odpowiedzi na to pytanie, należy szukać bezpośrednio w jednym z punktów kontraktu equals()-hashCode():jeżeli equals() na dwóch obiektach zwraca true to ich hash-Code-y są równe. Ale, jeżeli hashCody są równe to metodą equals() może zwracać true lub false.
W krótkich, żołnierskich słowach: jeżeli porównanie hashCode() obu obiektów zwraca false to obiekty są różne. Jeżeli zwraca true, wówczas spór rozstrzyga metoda equals().
Odpowiedź na pytanie 2: z powodów wdajnościowych. Mniej kosztowne jest porównanie (już obliczonych przecież) haszy obu obiektów niż wywoływanie na nich metody equals(). Jeżeli hash-e są różne to obiekty są różne - nie potrzeba wywoływać equals(). Implemetacją powyższej optymalizacji jest właśnie w/w instrukcja warunkowa (1).
Mam nadzieję, że już wiadomo dlaczego tak ważne jest poprawne zaimplementowanie metody hashCode() i equals(), zgodnie z zasadami ich kontraktów. Bez trzymania się tych zasad kod albo byłby mało wydajny albo niepoprawnie dodawał duplikaty.
Przykład:
@Overide
public int hashCode() {
return 1;
}
Załóżmy powyższą implementację meotdy hashCode() w klasie naszego obiektu. Zwraca dla każdego obiektu tą samą wartość. W tym przypadku, wszyskie dodawane obiekty trafiałyby pod ten sam adres w tablicy haszującej(do tego samego kubełka). Ale zanim obiekt zostałby dodany(lub odrzucony) lub gdbyśmy wyszukiwali obiektu w HashMap-ie, metoda equlas() byłaby wywoływana pomiędzy każdym nowym obiektem a już istniejącym - mało to optymalne. Mielibyśmy złożoność O(n) (lub ewentualnie O(logn) - ale to temat na bardziej zaawansowany artykuł)
Metody equals() oraz hashCode() zazwyczaj generujemy automatycznie, używając do tego IDE ( przyp. w IntelliJ skrót alt+insert ). Nic nie stoi jednak na przeszkodzie abyśmy sami sobie je zaimplementowali. Ważne jednak aby przestrzegać zasad kontraktu dla obu metod. Pełną treść kontraktu można znaleźć w dokumentacji Javy - link.
hashCode() nie jest unikatowy
Jeżeli kogoś nie satysfakcjonuje odpowiedź na pytanie pierwsze to bardzo dobrze, bo można do niej podejść z drugiej strony i wymaga ona głębszej analizy.
Jako przykład posłużyć nam może jeszcze jeden przypadek, gdy dwa unikatowe obiekty zwracają taki sam hashCode(). Teoretycznie jest to możliwe, choćby ze względu na skończoną ilość wartości int, a przecież nowych obiektów możemy tworzyć nieskończenie wiele. Praktycznie jednak, wewnętrznie metoda hashCode() została tak zaimplementowana, aby do tych powtórek za często nie dochodziło.
/*
int result = 31 * result + (element == null ? 0 : element.hashCode());
Gdybyśmy natrafili w naszym przykładzie na taki przypadek to oczywiście instrukcja warunkowa z poprzedniego akapitu(1) kwestię by odpowiednio rozwiązała.
Podsumowanie
Metody equals() oraz hashCode() zazwyczaj generujemy automatycznie w klasie naszego obiektu, używając do tego IDE ( przyp. w IntelliJ skrót alt+insert ). Nic nie stoi jednak na przeszkodzie abyśmy stworzyli je wg własnego pomysłu. Twórcy Javy nam na to pozwalają. Ważne jednak aby przestrzegać opracowanych przez nich zasad kontraktu dla obu metod. Wówczas mamy pewność poprawnego i zoptymalizowanego wydajnościowo działania tych struktur. Pełną treść kontraktu można znaleźć w dokumentacji Javy - link.
Temat zdecydowanie niewyczerpany. Może i nawet niekompletny ( w końcu dopiero aspiruję na juniora). Możnaby zapewne przejść płynnie do szczegółowej zasady działania przykładowego HashSetu. Dowiedzielibyśmy się, że HashSet działa w oparciu o HashMape. Wówczas należałoby wspomnieć też o obiekcie Entry, który tak naprawdę opakowuje nasz obiekt. O tym jak powstaje przechowująca go tablica haszująca. Jaki jest jej rozmiar inicjalizacyjny oraz jak i kiedy się powiększa. Jak wyliczany jest indeks w tablicy haszy.
Pytań dużo, czasu mało, bo tematów sporo. Jeżeli popełniłem w artykule jakieś karygodne błędy chętnie się o tym dowiem.